

Dr. Jack Dongarra from Oak Ridge National Lab, one of the founders of the Top500, was on hand for the event in China and shared a draft document that offers deep detail on the full scope of the Tianhe-2, which will, barring any completely unexpected surprises, far surpass the Cray-built Titan.
The 16,000-node Inspur-built Tianhe-2 is based on Ivy Bridge (32,000 sockets) and 48,000 Xeon Phi boards, meaning a total of 3,120,000 cores. Each of the nodes sports 2 Ivy Bridge sockets and 3 Phi boards.
According to Dongarra (Report of his visit to the National University for Defense Technology Changsha, China), there are some new and notable LINPACK results:
I was sent results showing a run of HPL benchmark using 14,336 nodes, that run was made using 50 GB of the memory of each node and achieved 30.65 petaflops out of a theoretical peak of 49.19 petaflops, or an efficiency of 62.3% of theoretical peak performance taking a little over 5 hours to complete. The fastest result shown was using 90% of the machine. They are expecting to make improvements and increase the number of nodes used in the test.
The system will be housed at the National Supercomputer Center in Guangzhou and has been aimed at providing an open platform for research and education and to provide a high performance computing service for southern China. It is the new Tianhe-2 (TH-2) also called the Milkyway-2 supercomputer.
There are a number of features of the TH-2 that are Chinese in origin, unique and interesting, including the TH-Express 2 interconnection network, the Galaxy FT-1500 16-core processor, the OpenMC programming model, their high density package, the apparent reliability and scalability of the system.

Interestingly, each of the Phi boards have 57 cores instead of 61. This is because they were early in the production cycle at the time and yield was an issue. Still each of the 57 cores can boast 4 threads of execution and each thread can hit 4 flops per cycle. By Dongarra’s estimate, the 1.1 GHz cycle time produces a theoretical peak of 1.003 teraflops for each Phi element.
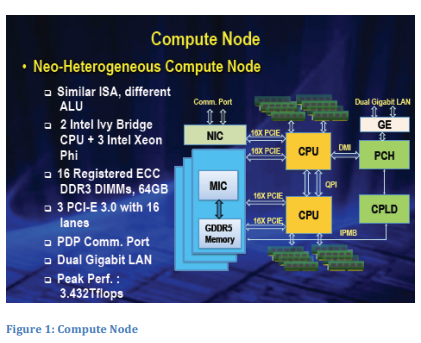
Each of the nodes is laden with 64 GB of memory, each of the Phi elements come with 8 GB of memory for a total of 88 GB of memory per node for a total of full system memory at 1.404 petabytes. There is not a lot of detail about the storage infrastructure, but there is a global shared parallel storage system sporting 12.4 petabytes.
According to Dongarra, there are “2 nodes per board, 16 boards per frame, 4 frames per rack, and 125 racks make up the system.” He says that the compute board has two compute nodes and is composed of two halves—the CPM and APM. The CPM portion of the board contains the 4 Ivy Bridge processors, memory and 1 Xeon Phi board while the CPM half contains the 5 Xeon Phi boards.


In addition to the compute nodes there is a frontend system composed of 4096 Galaxy FT-1500CPUs. These processors were designed and developed at NUDT. They are not considered as part of the compute system. The FT-1500 is 16 cores and based on SparcV9. It uses 40 nm technology and has a 1.8 GHz cycle time. Its performance is 144 Gflop/s and each chip runs at 65 Watts.By comparison the Intel Ivy Bridge has 12 cores uses 22 nm technology and has a 2.2 GHz cycle time with a peak performance of 211 Gflop/s.
The Interconnect
NUDT has built their own proprietary interconnect called the TH Express-2 interconnect network. The TH Express-2 uses a fat tree topology with 13 switches each of 576 ports at the top level. This is an optoelectronics hybrid transport technology. Running a proprietary network. The interconnect uses their own chip set. The high radix router ASIC called NRC has a 90 nm feature size with a 17.16×17.16 mm die and 2577 pins. The throughput of a single NRC is 2.56 Tbps. The network interface ASIC called NIC has the same feature size and package as the NIC, the die size is 10.76×10.76 mm, 675 pins and uses PCI-E G2 16X. A broadcast operation via MPI was running at 6.36 GB/s and the latency measured with 1K of data within 12,000 nodes is about 9 us.
The Software Stack
The Tianhe-2 is using Kylin Linux as the operating system. Kylin is an operating system developed by the National University for Defense Technology, and successfully approved by China’s 863 Hi-tech Research and Development Program office in 2006. See http://en.wikipedia.org/wiki/Kylin_(operating_system) for addition details. Kylin is compatible with other mainstream operating systems and supports multiple microprocessors and computers of different structures. The Kylin packages all include standard open source and public packages. This is the same OS used in the Tianhe-1A. Resource management is based on SLURM. They have a power-aware resource allocation and use multiple custom scheduling polices.
There are Fortran, C, C++, and Java compilers, OpenMP, and MPI 3.0 based on MPICH version 3.0.4 with custom GLEX (Galaxy Express) Channel support. They can do multichannel message data transfers, dynamic flow control and have offload collective operations. In addition, they are developed something called OpenMC. It is a directive based intra-node programming model. Think of it as a way to use OpenMC instead of Open-MP and either CUDA, OpenACC, or OpenCL. This new abstraction for hardware and software provides for a unified logical layer above all computing including CPU cores and Xeon Phi processors but could be extended to architectures with similar ISA and heterogeneous processors. They provide directives for high efficient SIMD operations and directives for high efficiency data locality exploitation and data communication. Open-MC is still a work in progress.
Energy Efficiency
To compute the flops/watt one can take the power under load for the whole system (processors, memory and interconnect) at 17.6 MW and divide by the percent of the machine used to run the benchmark, in this case 14,336 nodes of the total 16,000 nodes or 90% of the machine. The performance achieved was 30.65 Pflop/s or 1.935 Gflop/Watt.
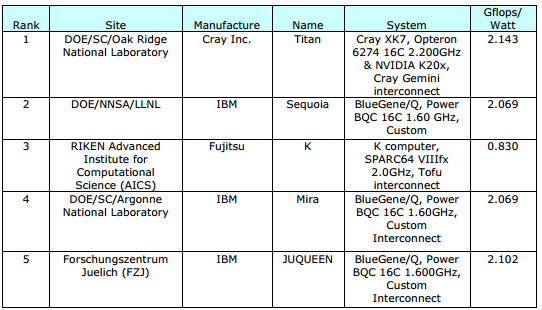
The Top 5 systems on the Top 500 list have the following Gflops/Watt efficiency.
If you liked this article, please give it a quick review on ycombinator or StumbleUpon. Thanks

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.