

The SpiNNaker project aims to develop parallel computer systems with more than a million embedded processors. The goal of the project is to support largescale simulations of systems of spiking neurons in biological real time, an application that is highly parallel but also places very high loads on the communication infrastructure due to the very high connectivity of biological neurons. The scale of the machine requires fault-tolerance and power-efficiency to influence the design throughout, and the development has resulted in innovation at every level of
design, including a self-timed inter-chip communication system that is resistant to glitch-induced deadlock and ‘emergency’ hardware packet re-routing around failed inter-chip links, through to run-time support for functional migration and real-time fault mitigation.
The embedded processor (ARM) technology employed in SpiNNaker delivers a similar performance to a PC from each 20-processor node, for a component cost of around $20 and a power consumption under 1 Watt. One million processors will cost about $1 million.
To simulate 90 billion neurons will take 100 times more cores than the SpiNNaker system will have.
SpiNNaker, which stands for Spiking Neural Network architecture, aims to map the brain’s functions for the purpose of helping neuroscientists, psychologists and doctors understand brain injuries, diseases and other neurological conditions. The project is being run out of a group at University of Manchester, which designed the system architecture, and is being funded by a £5m grant from the Engineering and Physical Sciences Research Council (EPSRC). Other elements of the SpiNNaker system are being developed at the universities of Southampton, Cambridge and Sheffield.


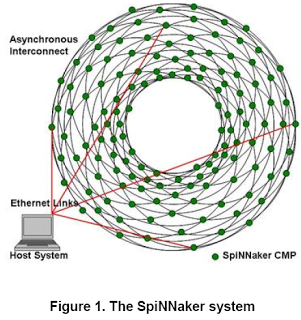
SpiNNaker is conceived as a two-dimensional toroidal mesh of chip multiprocessors (CMPs) connected via Ethernet links to one or more host machines (Fig. 1). The 2-D mesh has triangular facets (Fig. 2) to support ‘emergency routing’ around a failed or congested link. Each CMP node comprises two chips: a SpiNNaker MPSoC and a 1Gbit mobile DDR SDRAM memory. The SpiNNaker MPSoC incorporates up to 20 ARM968 processors, each with local memory and support peripherals, interconnected by two self-timed Network-on-Chip (NoC) fabrics developed using tools and libraries supplied by Silistix Ltd
* The Communications NoC carries neural spike event packets between processors on the same and different nodes.
* The System NoC is used as a general-purpose onchip interconnect to allow processors to access system resources such as the shared SDRAM.
The feature of the architecture that renders it uniquely suited to modeling large-scale systems of spiking neurons is the Communications NoC and the associated multicast Packet Router on each node. Each neuron that emits a spike causes its host processor to generate a 40-bit packet that contains 8 bits of packet management data and a 32-bit identifier of the neuron that fired. Identifying neuron spikes by using a unique identifier for the source neuron is known as Address Event Representation (AER), and has been used for some time by the neuromorphic community. In the past AER has been used principally in bus-based broadcast communication between neurons, but here we employ a packetswitched multicast mechanism to reduce total communication loading.
The SpiNNaker project aims to deliver costeffective parallel computing resources at an unprecedented scale, with over a million embedded processors delivering around 200 teraIPS to support the simulation of a billion spiking neurons in biological real time. The scale of the system demands that powerefficiency and fault-tolerance feature prominently among the design criteria, and the result is a design that embodies concurrency at all levels, from circuit through system to application.
Many challenges remain, since we have yet to gain access to silicon so many of the ideas presented here have yet to be proven “in the flesh”. But we have exposed the design to extensive simulation, up to and including running real-time spiking neuron application code on SystemC and Verilog RTL models incorporating four chips and eight ARM968 processors, so we are gaining considerable experience in driving the system in full detail. There is still a long way to go, however, before the machine will be ready for use by neuroscientists and psychologists who do not wish to have to contend with concurrency issues at any level below the neurological model that they wish to simulate.
Understanding how the brain develops, learns and adapts remains as one of the Grand Challenges of science. A new computer, however powerful and welladapted to running models of the brain, is not going to solve this mystery in a single step. It is merely a tool alongside a whole range of other tools in neuroscience and psychology that offer perspectives on the problem. As an example of concurrency in action, however, the brain is supreme, and new theories of concurrency are likely to be required before any real understanding of the principles of operation of the brain can emerge, to complement the modeling capabilities of machines such as SpiNNaker and many other ongoing developments in neuroscience and psychology.
If you liked this article, please give it a quick review on ycombinator or StumbleUpon. Thanks

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.